Generating Language
Synthesis
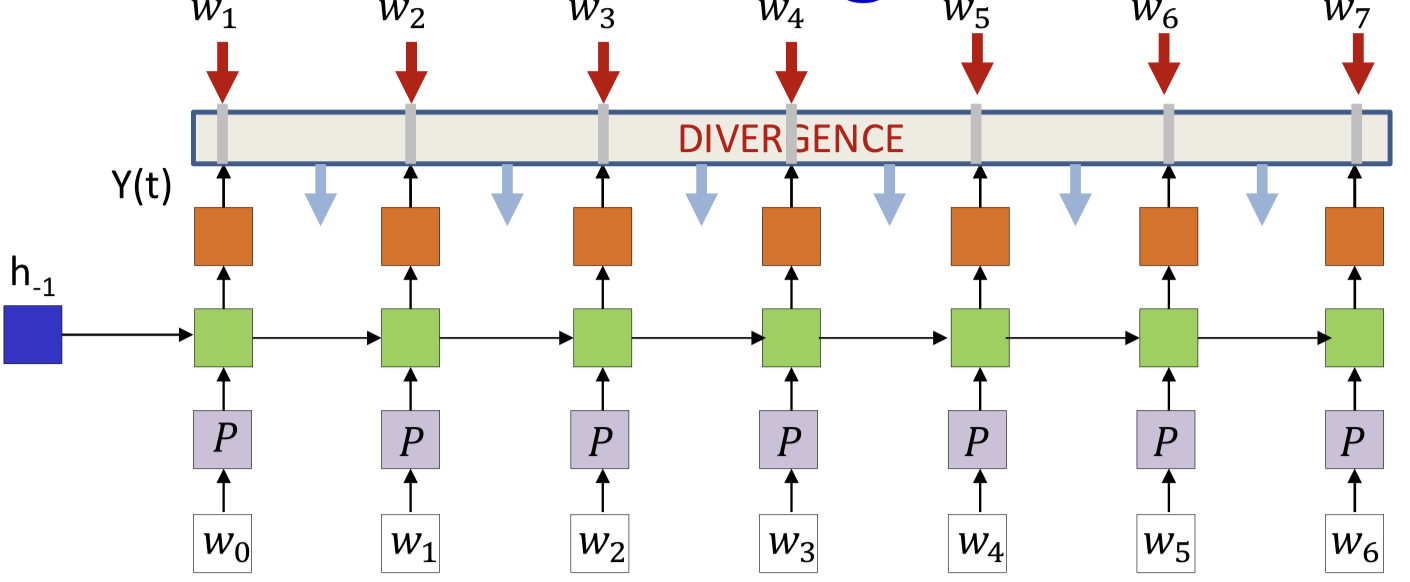
- Input: symbols as one-hot vectors
- Dimensionality of the vector is the size of the 「vocabulary」
- Projected down to lower-dimensional “embeddings”
- The hidden units are (one or more layers of) LSTM units
- Output at each time: A probability distribution that ideally assigns peak probability to the next word in the sequence
- Divergence
Div(Ytarget(1…T),Y(1…T))=∑_tXent(Y_target(t),Y(t))=−∑_tlogY(t,w_t+1)
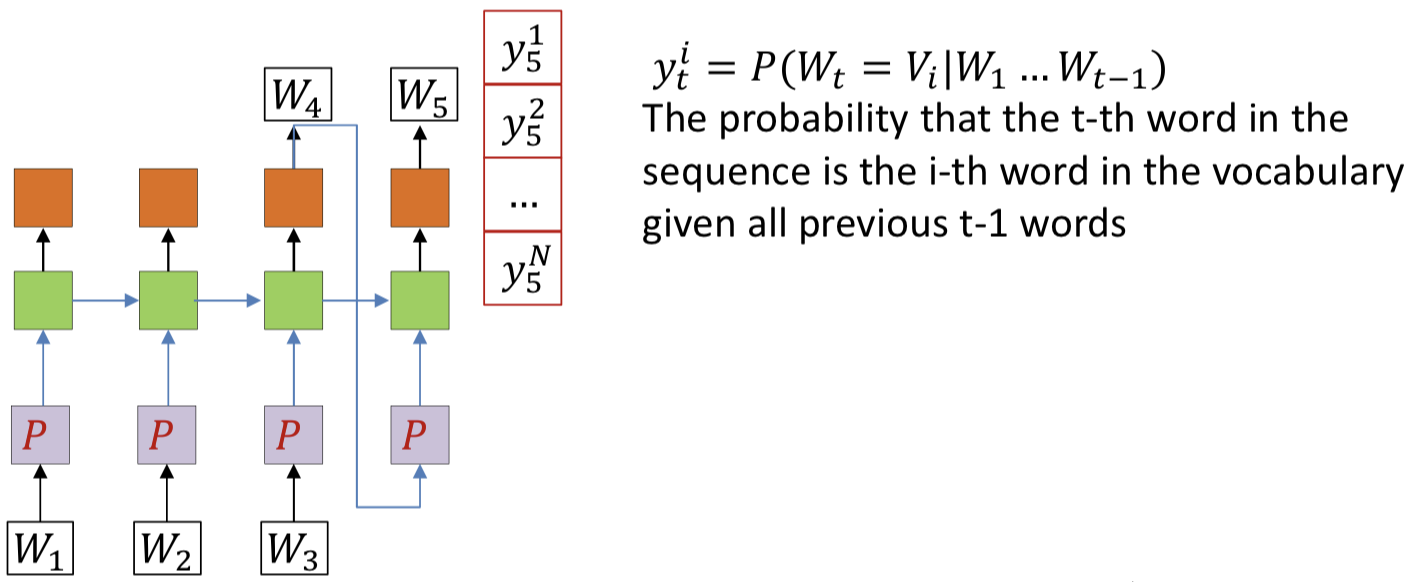
- Feed the drawn word as the next word in the series
- And draw the next word from the output probability distribution
Beginnings and ends
- A sequence of words by itself does not indicate if it is a complete sentence or not
- To make it explicit, we will add two additional symbols (in addition to the words) to the base vocabulary
<sos>: Indicates start of a sentence<eos> : Indicates end of a sentence
- When do we stop?
- Continue this process until we draw an
<eos>
- Or we decide to terminate generation based on some other criterion
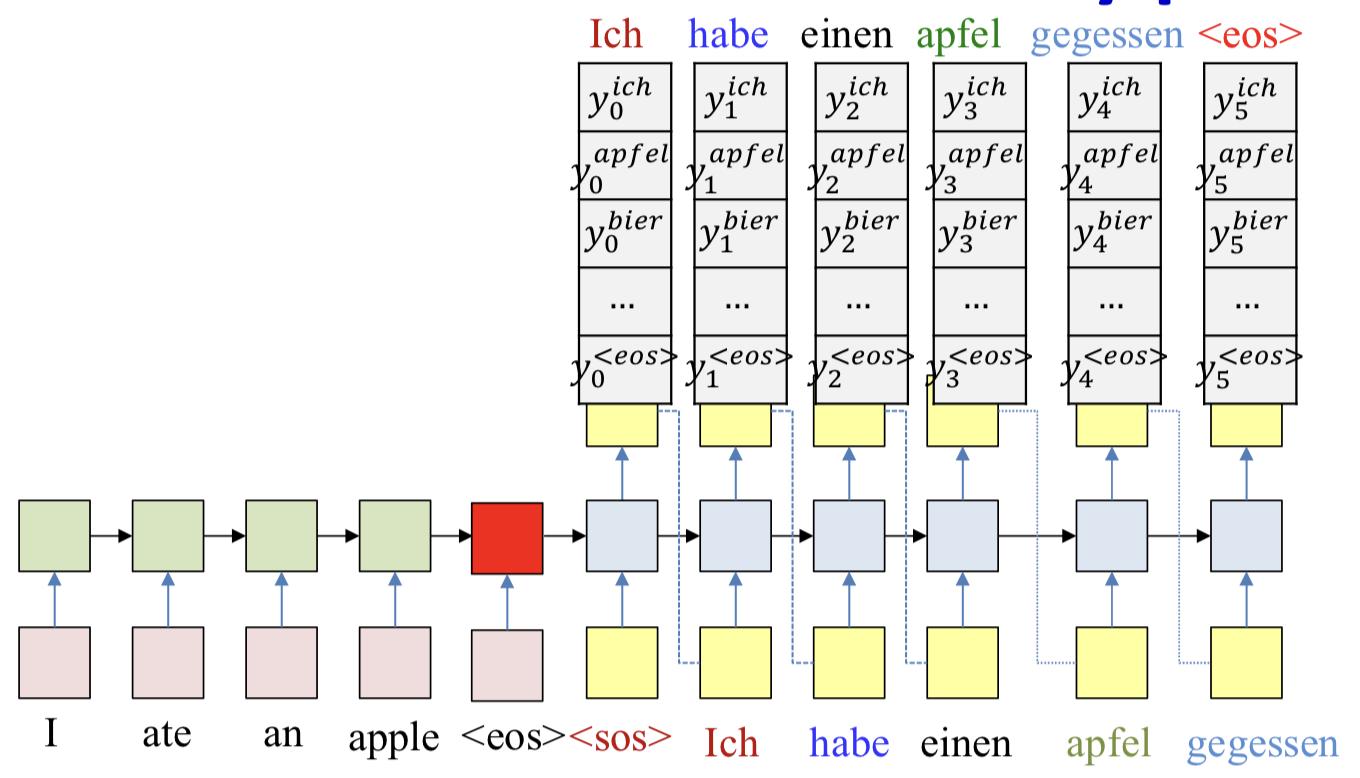
Delayed sequence to sequence
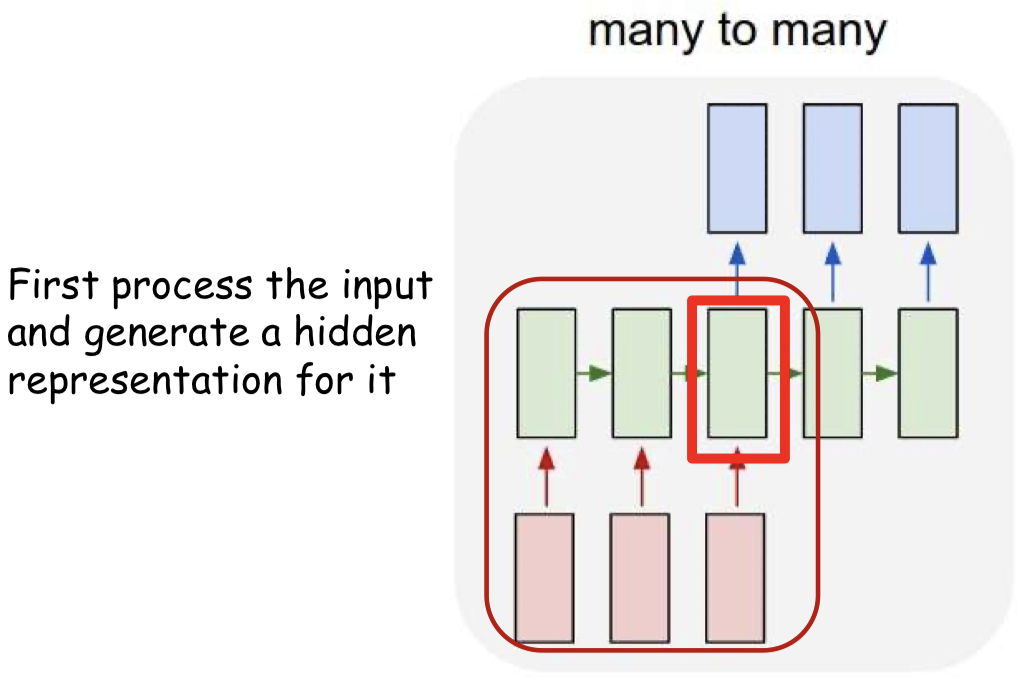
Pseudocode

- Problem: Each word that is output depends only on current hidden state, and not on previous outputs
- The input sequence feeds into a recurrent structure
- The input sequence is terminated by an explicit
<eos> symbol
- The hidden activation at the
<eos> “stores” all information about the sentence
- Subsequently a second RNN uses the hidden activation as initial state to produce a sequence of outputs
- The output at each time becomes the input at the next time
- Output production continues until an
<eos> is produced
Autoencoder
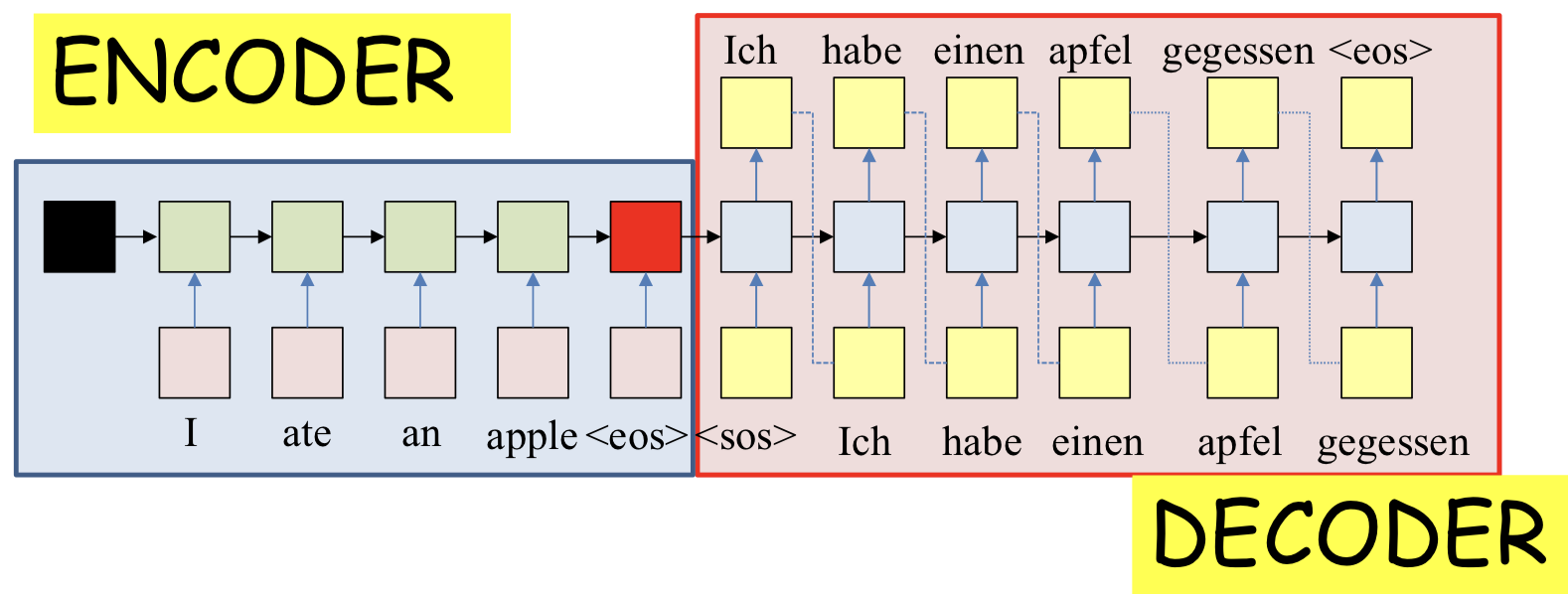
- The recurrent structure that extracts the hidden representation from the input sequence is the encoder
- The recurrent structure that utilizes this representation to produce the output sequence is the decoder
Generating output
- At each time the network produces a probability distribution over words, given the entire input and previous outputs
- At each time a word is drawn from the output distribution
P(O1,…,OL∣W1in,…,WNin)=y1O1y1O2…y1OL
- The objective of drawing: Produce the most likely output (that ends in an
<eos>)
O1,…,OLargmaxy1O1y1O2…y1OL
- How to draw words?
- Greedy answer
- Select the most probable word at each time
- Not good, making a poor choice at any time commits us to a poor future
- Randomly draw a word at each time according to the output probability distribution
- Not guaranteed to give you the most likely output
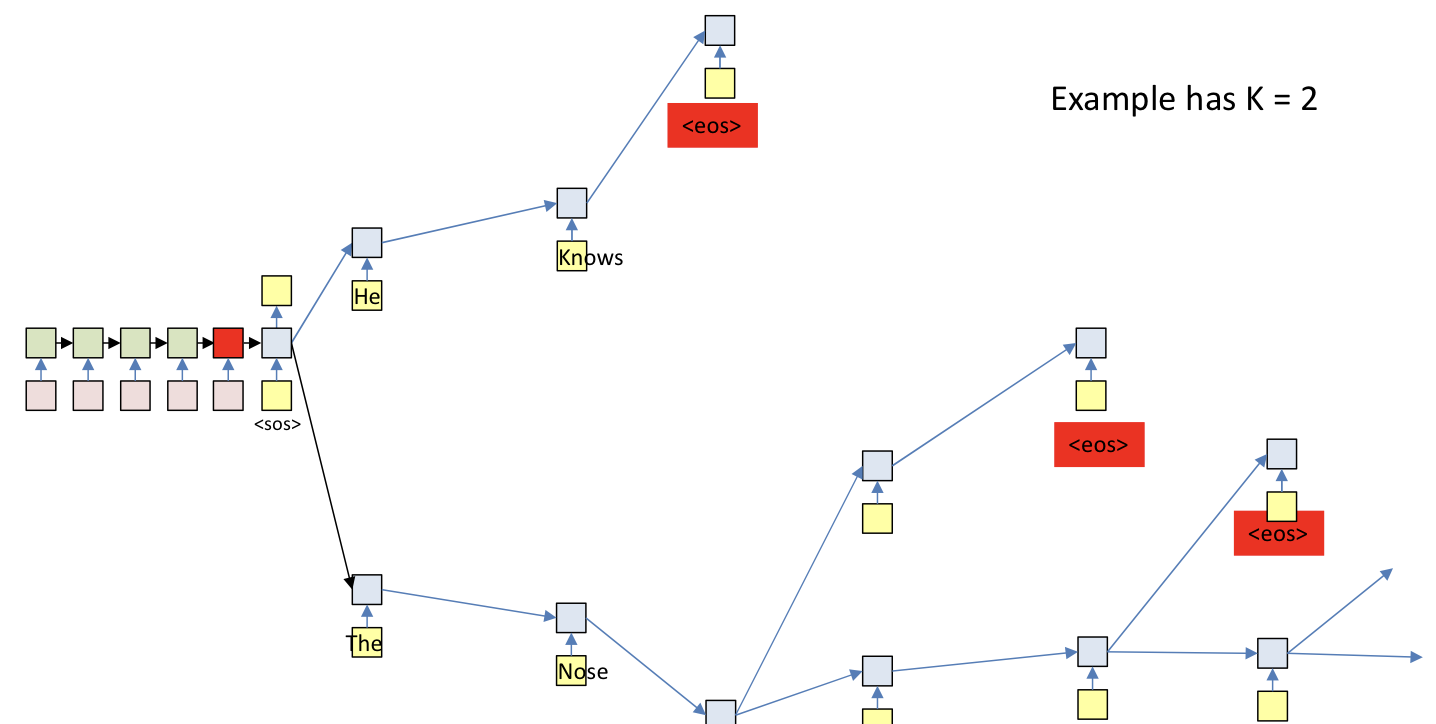
- Beam search
- Search multiple choices and prune
- At each time, retain only the top K scoring forks
- Terminate: When the current most likely path overall ends in
<eos>
Train
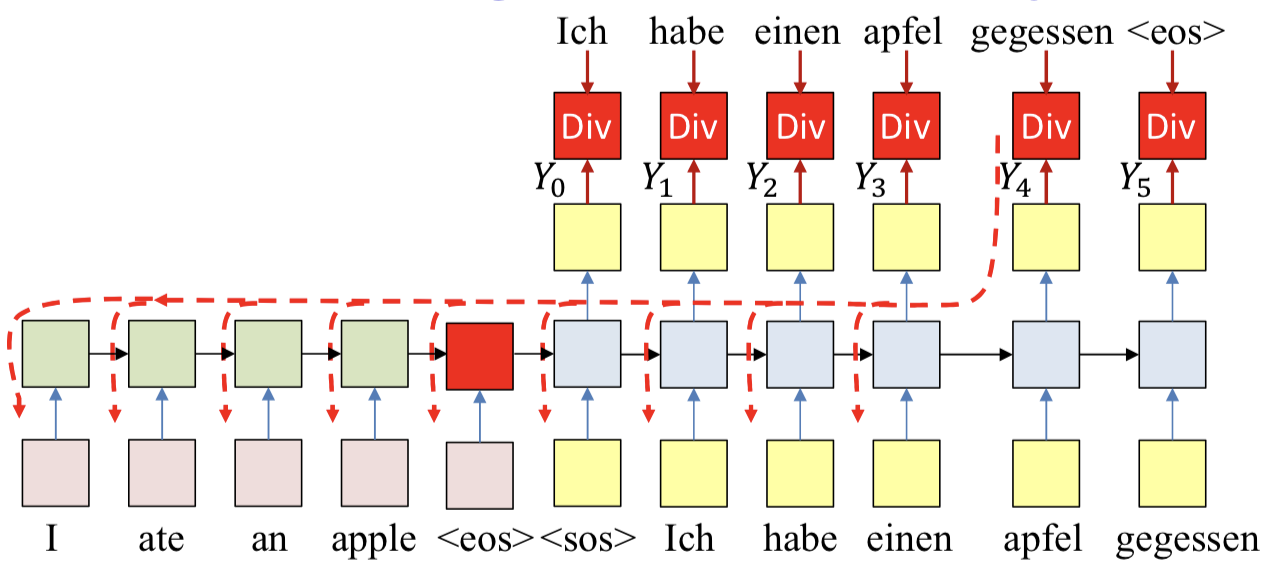
- In practice, if we apply SGD, we may randomly sample words from the output to actually use for the backprop and update
- Randomly select training instance: (input, output)
- Forward pass
- Randomly select a single output y(t) and corresponding desired output d(t) for backprop
- Trick
- The input sequence is fed in reverse order
- This happens both for training and during actual decode
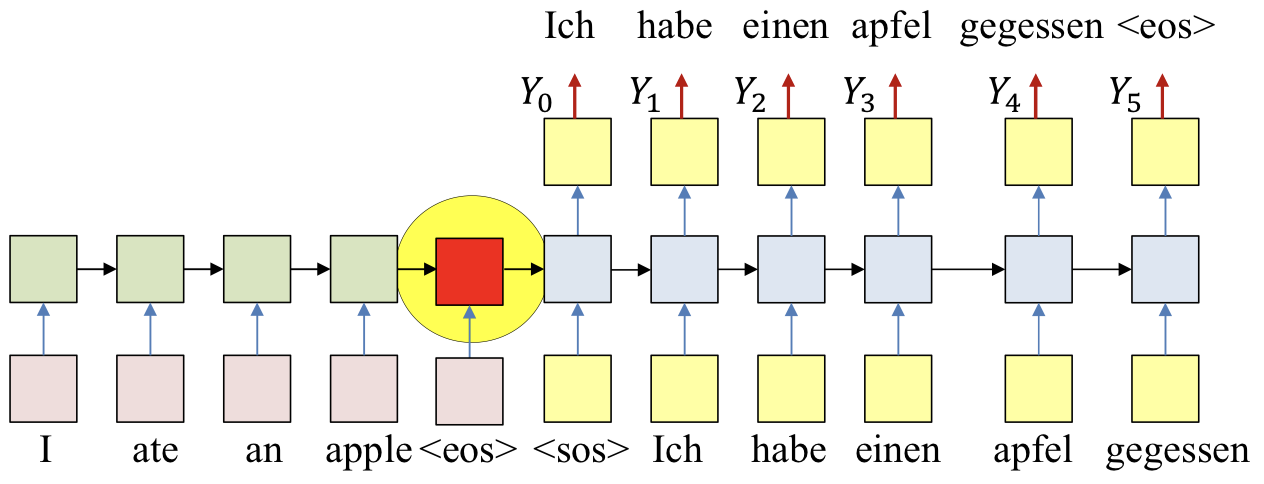
- Problem
- All the information about the input sequence is embedded into a single vector
- In reality: All hidden values carry information
Attention model
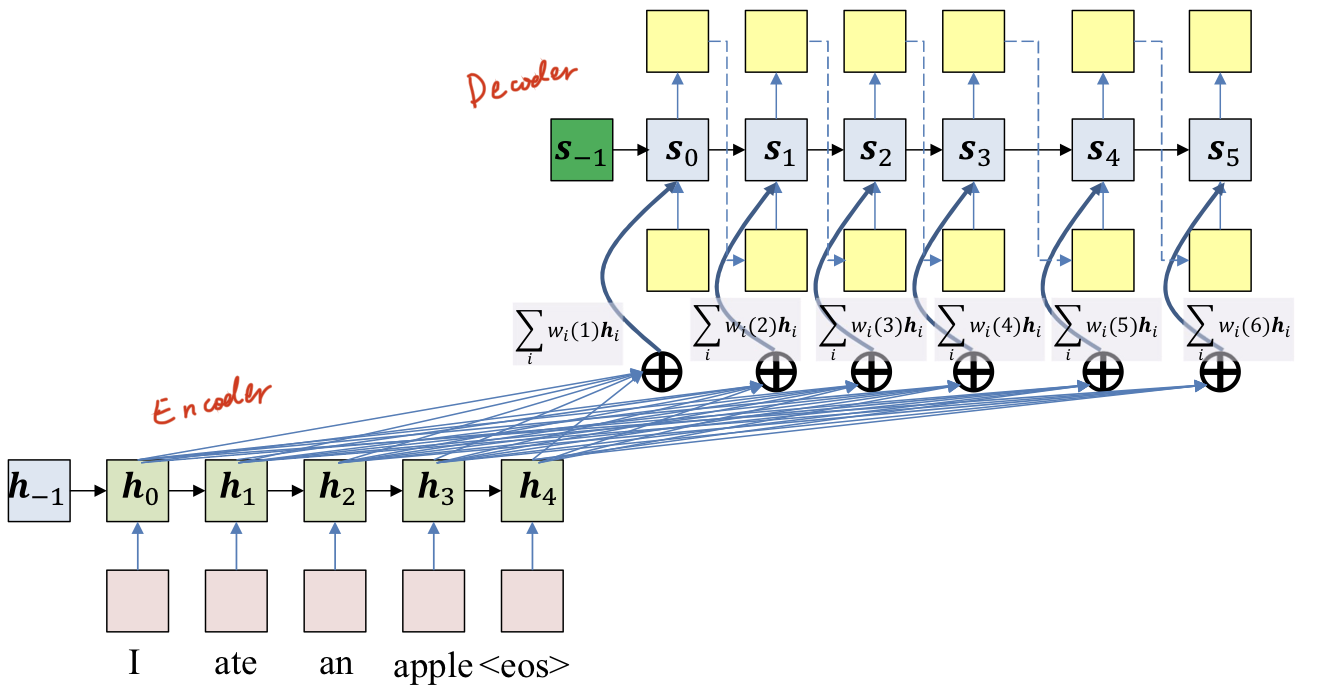
- Compute a weighted combination of all the hidden outputs into a single vector
- Weights vary by output time
- Require a time-varying weight that specifies relationship of output time to input time
- Weights are functions of current output state
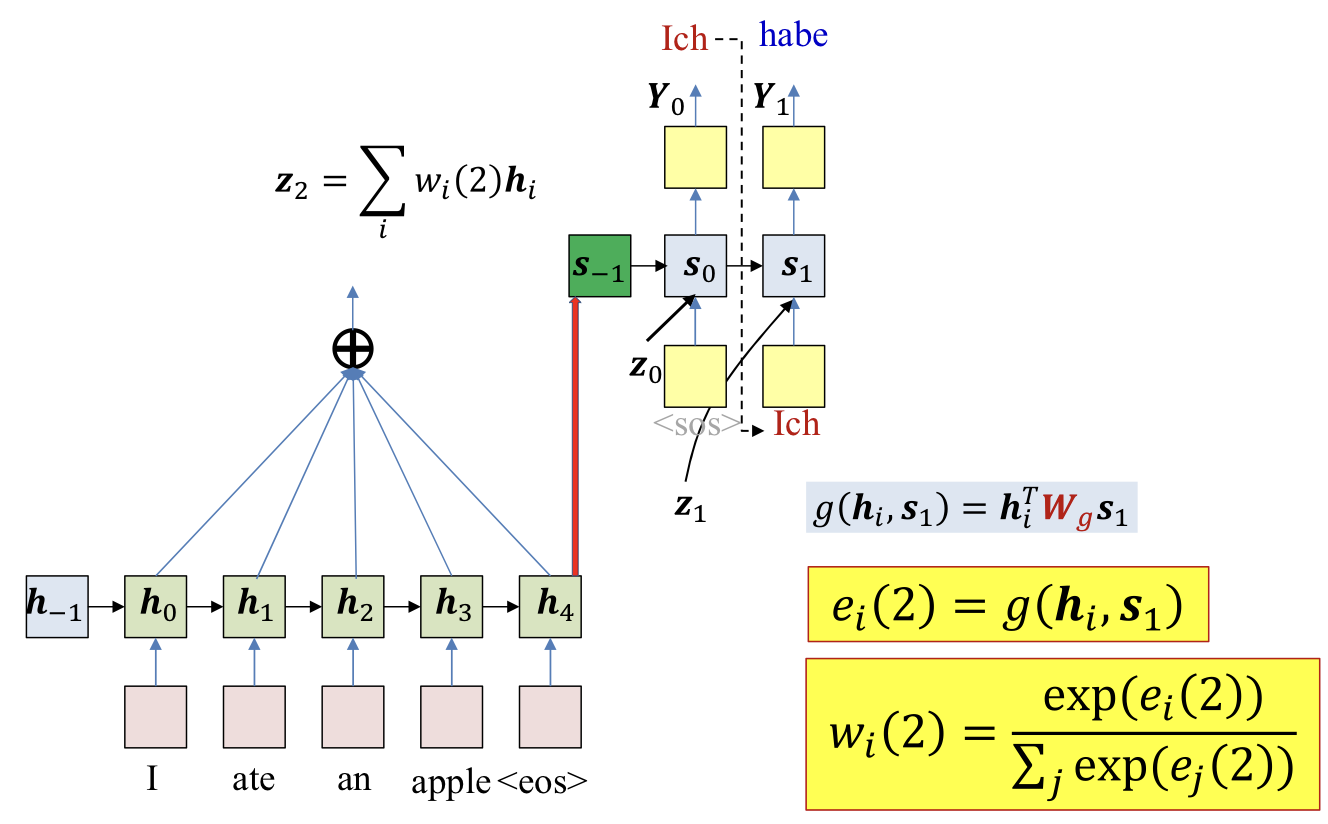
ei(t)=g(hi,st−1)
wi(t)=∑jexp(ej(t))exp(ei(t))
Attention weight
- Typical option for g()
- Inner product
- g(h_i,s_t−1)=h_iTs_t−1
- Project to the same demension
- g(hi,s_t−1)=h_iTW_gs_t−1
- Non-linear activation
- g(h_i,s_t−1)=v_gTtanh⎝⎛W_g⎣⎡his_t−1⎦⎤⎠⎞
- MLP
- g(h_i,s_t−1)=MLP([h_i,s_t−1])
Pseudocode

Train
- Back propagation also updates parameters of the “attention” function
- Trick: Occasionally pass drawn output instead of ground truth, as input
- Randomly select from output, force network to produce correct word even the prioir word is not correct
variants
- Bidirectional processing of input sequence
- Local attention vs global attention
- Multihead attention
- Derive 「value」, and multiple 「keys」 from the encoder
- Vi,Kil,i=1…T,l=1…Nhead
- Derive one or more 「queries」 from decoder
- Qjl,j=1…M,l=1…Nhead
- Each query-key pair gives you one attention distribution
- And one context vector
- aj,il=attention(Qjl,Kil,i=1…T),Cjl=∑iaj,ilVi
- Concatenate set of context vectors into one extended context vector
- Cj=[Cj1Cj2…CjNhead]
- Each 「attender」 focuses on a different aspect of the input that’s important for the decode